Scraping Websites

Eric Robsky Huntley, PhD (They/them)
- Lecturer in Urban Science and Planning
- ehuntley@mit.edu
Tutorial Information
- Module 3 in Spatial Data Science.
Methods
Tools
The idea behind webs craping is this: gather data quickly and replicably from websites by taking advantage of the fact that web pages are structured documents. While they are individually idiosyncratic, they tend to be internally consistent. This means that web scraping is always a bespoke affair—you can’t build a web scraper that will simply work in a generalizable way for all pages. However, there are general principles that, when rehearsed, will allow you to develop a scraper for a given website without too much effort.
The scraper we’re going to build today downloads key information about DUSP faculty from the DUSP website’s ‘people’ list. We’re going to scrape information about affiliation, navigate through weblinks, and download photos. Along the way, we’ll be doing some neat tricks—naming downloaded photos such that their nomenclature is consistent and dealing with missing and inaccessible information.
To do this, we’ll be using a couple of Python packages. The first is
bs4, or Beautiful Soup 4. This is an HTML and XML parser
which takes a downloaded web page and gives us objects and methods for
navigating its structure inuititively. It’s a very, very standard tool
for use in web scraping applications. We’ll also be using
wget to download files, and requests to
request webpages.
As such, the first thing you’ll need to do is install these packages.
Assuming you’ve created and activated your virtual environment, you’ll
want to install these packages using pip.
pip install requests wget bs4import requests
from pprint import pprint
from bs4 import BeautifulSoup
import wgetHaving imported our modules, we want to provide the base url of the
page we’re trying to scrape: in this case, the DUSP people list,
available at https://dusp.mit.edu/people. We then pass this
URL to the requests package’s get method,
which downloads the content of the page.
base_url = 'http://dusp.mit.edu/people'
base_page = requests.get(base_url)
print(base_page)<Response [200]>A 200 code in the response tells you the request was
successful. Beautiful soup will now allow us to parse the
downloaded HTML, to render it navigable by BeautifulSoup’s fairly rich
array of methods to navigate a page’s Document Object Model, or DOM. We
do this by creating a new object of the BeautifulSoup class, which takes
the page’s content as its input, and also takes an argument that
identifies which parser to use (here, we use
html.parser).
soup = BeautifulSoup(base_page.content, 'html.parser')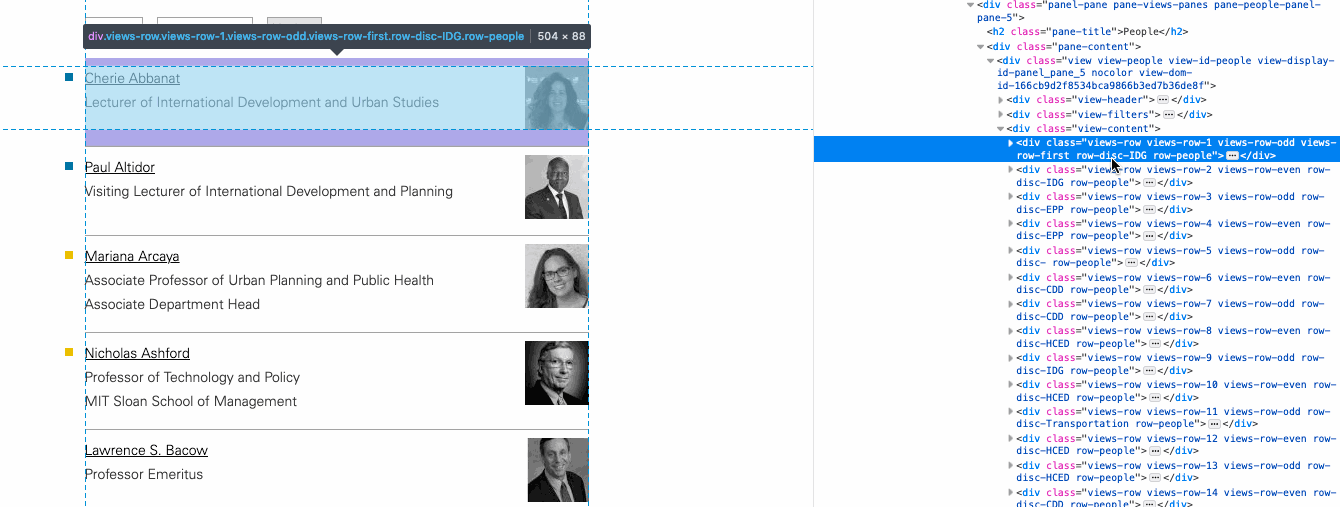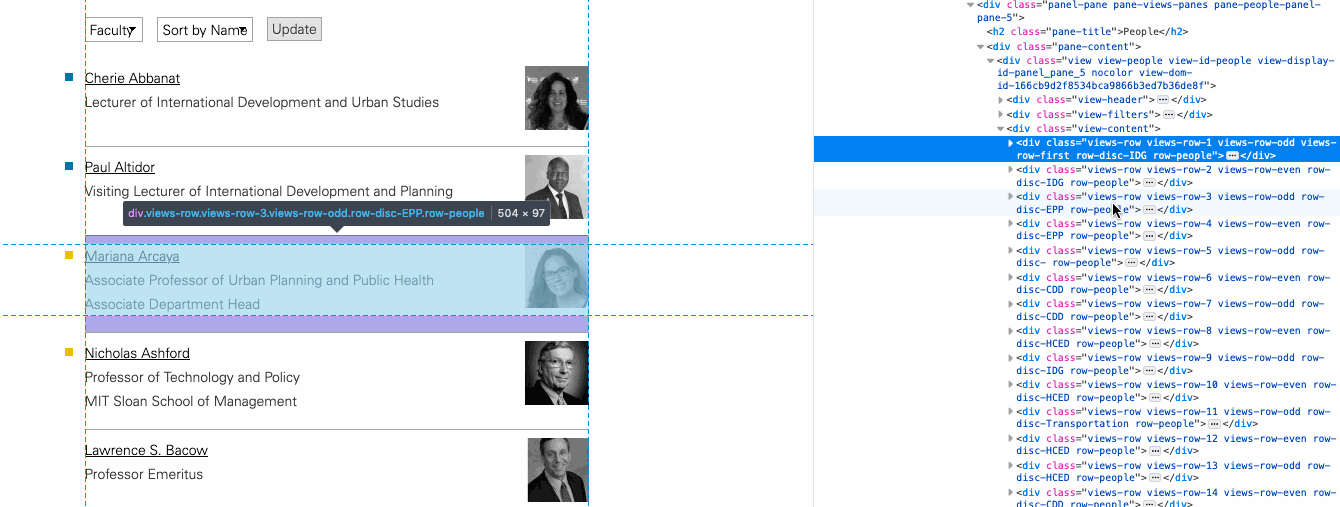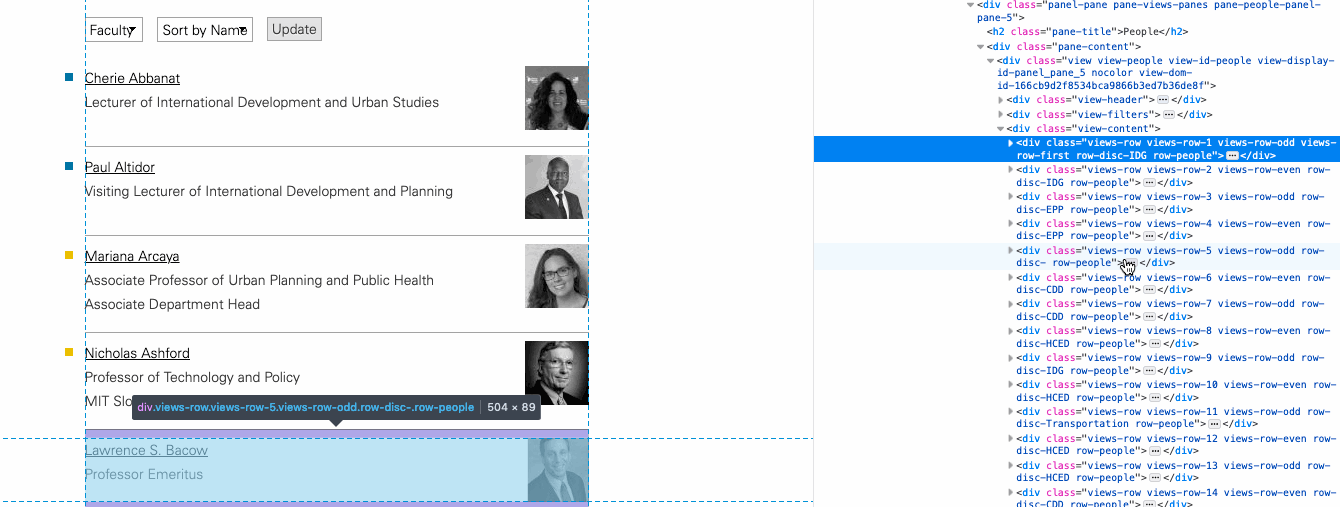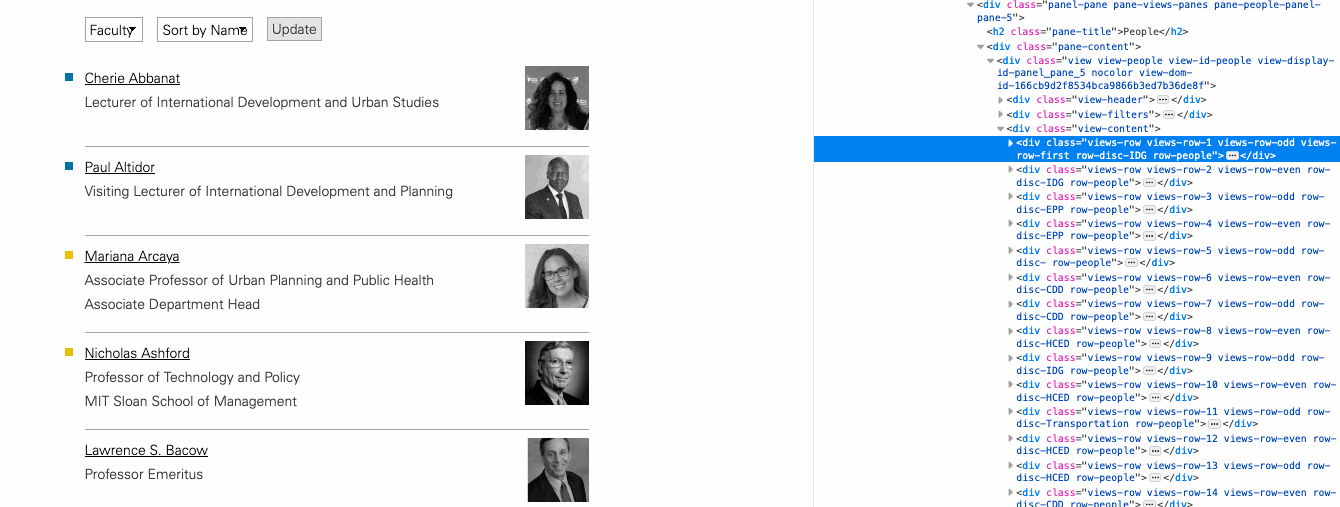
We can now use a web browser to do some digging—we can inspect the
elements in the webpage to find that each ‘person’ is held in a
div with the class row-people. As such, we can
tell BeautifulSoup to find all instances of div tags with
the class row-people. We print only the first person to
save space.
people = soup.find_all('div', class_='row-people')
pprint(people[0])<div class="views-row views-row-1 views-row-odd views-row-first row-disc-IDG row-people">
<div> <span><div class="bull"></div></span> </div>
<div class="views-field views-field-field-user-picture"> <div class="field-content"><img alt="" src="http://dusp.mit.edu/sites/dusp.mit.edu/files/styles/profile_pic/public/user/pictures/cherie.jpg?itok=tqCmbLrz"/></div> </div>
<div class="views-field views-field-name"> <span class="field-content"><a class="username" href="/faculty/cherie-abbanat" title="View user profile.">Cherie Abbanat</a></span> </div>
<div class="views-field views-field-field-position-and-title-1"> <div class="field-content">Lecturer of International Development and Urban Studies</div> </div>
<div class="views-field views-field-field-position-and-title-2"> <div class="field-content"></div> </div>
<div class="views-field views-field-field-other-division"> <div class="field-content"></div> </div> </div>Now that we have found all elements with, and we can access each
element’s components using the element class’s methods. For example, we
can get all text contained within the div by using the
get_text() method.
pprint(people[0].get_text())('\n'
' \n'
' \n'
' Cherie Abbanat \n'
' Lecturer of International Development and Urban Studies \n'
' \n'
' ')The text is surrounded by a number of line breaks, which are
represented by the \n characters—this is how you say ‘new
line!’ in ASCII character encoding. As such, it’s often a good idea to
use the strip() method to remove new line and space
characters before and after a given chunk of text.
pprint(people[0].get_text().strip())'Cherie Abbanat \n Lecturer of International Development and Urban Studies'Better! But we don’t want all text—we want to be careful and save specifically those pieces of information that are useful to us. Again, we can examine the document structure and notice that…
- Faculty names are stored as text that is wrapped in an
atags with the classusername. - Faculty pages are stored as
hrefreferences in that sameatag. - Faculty positions and titles are included in two separate
fields—both
divs with classesviews-field-field-position-and-title-1and...-2, respecitvely. - There’s an additional field that stores additional affiliations,
stored in a
divwith classviews-field-other-division.
Using this knowledge, we can iterate over the people
list we produced above, finding each of those classes
within each faculty div. This looks like this:
for person in people[0:3]:
name_href = person.find('a', class_='username')
name = name_href.get_text()
href = name_href.get('href')
pos_1 = person.find('div', class_='views-field-field-position-and-title-1').get_text()
pos_2 = person.find('div', class_='views-field-field-position-and-title-2').get_text()
other = person.find('div', class_='views-field-field-other-division').get_text()
print(name, href, pos_1, pos_2, other)Cherie Abbanat /faculty/cherie-abbanat Lecturer of International Development and Urban Studies
Paul Altidor /faculty/paul-altidor Visiting Lecturer of International Development and Planning
Mariana Arcaya /faculty/mariana-arcaya Associate Professor of Urban Planning and Public Health Associate Department Head But this is only a summary page—much of the information about each
faculty member is stored on their faculty page. Using a combination of
requests and BeautifulSoup we can navigate to
each faculty page as we encounter it and draw additional data.
We grabbed everything we need to do this above: we stored the path to
the faculty page in the href variable. This is a relative
path, meaning that it doesn’t include a web address—only a path relative
to the current page. We can therefore append the relative path to the
base_url—this happens on the line reading
...BeautifulSoup(requests.get(base_url + href).content....
On each faculty’s page we can, for example, pull their biography,
which we determine is located in a div with the class
pane-user-field-bio.
base_url = 'http://dusp.mit.edu'
for person in people[0:3]:
name_href = person.find('a', class_='username')
name = name_href.get_text()
href = name_href.get('href')
pos_1 = person.find('div', class_='views-field-field-position-and-title-1').get_text()
pos_2 = person.find('div', class_='views-field-field-position-and-title-2').get_text()
other = person.find('div', class_='views-field-field-other-division').get_text()
if href:
person_soup = BeautifulSoup(requests.get(base_url + href).content, 'html.parser')
bio = person_soup.find('div', class_='pane-user-field-bio').get_text()
print(name, href, pos_1, pos_2, other, bio)Cherie Abbanat /faculty/cherie-abbanat Lecturer of International Development and Urban Studies
Cherie is a lecturer at DUSP and in the Department of Architecture where she has been teaching for over fifteen years. Cherie lectures on policy, non-profit management, post-disaster rebuilding in New Orleans and Haiti, and the need for grassroots initiatives.
As a practitioner, Cherie joined Haiti Projects Inc., a 501 (c)3 non-profit, in 2013 as its CEO to transform Haiti Projects from a fledgling non-profit into a growing social enterprise. Cherie successfully turned Haiti Projects around financially and the non-profit is ready to grow. Haiti Projects boasts 4 employees in the US and close to 90 employees in Haiti. Haiti Projects operates a women's sewing cooperative, a women's health clinic that focuses on family planning, health and hygiene, and a community library. With support from the Kellogg Foundation, Haiti Projects plans to build a new community multi-purpose center in 2015.
As a Haitian American, Cherie is passionate about empowering women in Haiti and throughout the world.
Cherie has her undergraduate degree in Economics and French from Simmons College and her Masters with a concentration in Environmental Policy and Planning from the Massachusetts Institute of Technology (MCP '97).
Paul Altidor /faculty/paul-altidor Visiting Lecturer of International Development and Planning
Paul Getty Altidor was named Ambassador Extraordinary and Plenipotentiary of Haiti to the United States in 2012; he presented his credentials to then-President Barack Obama on May 2. He served in this capacity 2019.
Ambassador Altidor spent his early years where he was born in Jérémie, Haiti. He attended primary school in Jérémie then studied at the Centre d’Etudes Secondaire in Port au Prince. His family later moved to Boston where he completed his secondary education. Ambassador Altidor received his undergraduate degree from Boston College. He earned an MS degree from MIT in Urban Studies and Planning (2004) and also pursued graduate studies in law and economics in France.
Ambassador Altidor has an extensive private sector background. As a management consultant, he counseled firms in different countries on corporate governance and responsibility. In the aftermath of the 2010 earthquake, Ambassador Altidor led a team of professors and researchers from the Massachusetts Institute of Technology’s Community Innovators Lab down to Haiti. At the request of Haitian authorities, the team provided guidance to reconstruction officials on housing policy and financing.
Prior to the earthquake in Haiti, Ambassador Altidor worked at the International Finance Corporation (IFC) where he advised governments on infrastructure projects and public-private partnerships. He has also worked for the World Bank. Ambassador Altidor has taught at Ecole Supérieure Catholique de Droit de Jérémie (ESCDROJ), a law school in his native town of Jérémie, and he is a frequent speaker at universities in Haiti and the United States.
Mariana Arcaya /faculty/mariana-arcaya Associate Professor of Urban Planning and Public Health Associate Department Head
Mariana Arcaya is a social epidemiologist and urban planner whose work explores dynamic relationships between geographic contexts, particularly neighborhoods, and health. Mariana conducts scholarly and policy-relevant research in two main areas: 1) bi-directional relationships between place and health, including how health considerations shape socioeconomic outcomes for individuals and communities, and, 2) applied and translational research on the social determinants of health, particularly health risk factors shaped by urban policy and planning decisions.
Prior to coming to MIT in 2015, Mariana served as a post-doctoral fellow at the Harvard Center for Population and Development Studies. She holds a Doctorate of Science from the Harvard School of Public Health, and a Master of City Planning from MIT's Department of Urban Studies & Planning. Her professional work experience includes instituting and managing a Public Health Division within Metropolitan Boston’s regional planning agency, as well as designing and overseeing the implementation of healthy urban planning strategies under a federally funded Community Transformation Grant.
We can extend this by locating the fields that contain, for example,
faculty bios, offices, emails, and interests. Here, we introduce a
slight complication—we test for the existence of a given field before
trying to extract its text. This is because if we try to extract text
(get_text()) from a field that doesn’t exist, Python will
throw an error and our script will stop executing. When you’re writing
scrapers this is a very common approach—while websites are structured,
not all pages are going to contain all information, nor are all pages
going to contain all information represented in a manner that is
consistent. As such, much of the work of scraping is introducing tests
that keep your script from failing when it encounters an exception.
for person in people[0:3]:
name_href = person.find('a', class_='username')
name = name_href.get_text()
href = name_href.get('href')
pos_1 = person.find('div', class_='views-field-field-position-and-title-1').get_text()
pos_2 = person.find('div', class_='views-field-field-position-and-title-2').get_text()
other = person.find('div', class_='views-field-field-other-division').get_text()
if href:
person_soup = BeautifulSoup(requests.get('http://dusp.mit.edu' + href).content, 'html.parser')
bio = person_soup.find('div', class_='pane-user-field-bio')
if bio:
bio = bio.get_text()
office = person_soup.find('div', class_='views-field views-field-field-office')
if office:
office = office.get_text()
email = person_soup.find('div', class_='views-field views-field-field-secondary-email')
if email:
email = email.get_text()
interests = person_soup.find('strong', class_='views-label views-label-field-areas-of-interest')
if interests:
interests = interests.next_sibling.next_sibling.get_text()
print(name, href, pos_1, pos_2, other, bio, office, email, interests)Cherie Abbanat /faculty/cherie-abbanat Lecturer of International Development and Urban Studies
Cherie is a lecturer at DUSP and in the Department of Architecture where she has been teaching for over fifteen years. Cherie lectures on policy, non-profit management, post-disaster rebuilding in New Orleans and Haiti, and the need for grassroots initiatives.
As a practitioner, Cherie joined Haiti Projects Inc., a 501 (c)3 non-profit, in 2013 as its CEO to transform Haiti Projects from a fledgling non-profit into a growing social enterprise. Cherie successfully turned Haiti Projects around financially and the non-profit is ready to grow. Haiti Projects boasts 4 employees in the US and close to 90 employees in Haiti. Haiti Projects operates a women's sewing cooperative, a women's health clinic that focuses on family planning, health and hygiene, and a community library. With support from the Kellogg Foundation, Haiti Projects plans to build a new community multi-purpose center in 2015.
As a Haitian American, Cherie is passionate about empowering women in Haiti and throughout the world.
Cherie has her undergraduate degree in Economics and French from Simmons College and her Masters with a concentration in Environmental Policy and Planning from the Massachusetts Institute of Technology (MCP '97).
9-520 abbanat@mit.edu None
Paul Altidor /faculty/paul-altidor Visiting Lecturer of International Development and Planning
Paul Getty Altidor was named Ambassador Extraordinary and Plenipotentiary of Haiti to the United States in 2012; he presented his credentials to then-President Barack Obama on May 2. He served in this capacity 2019.
Ambassador Altidor spent his early years where he was born in Jérémie, Haiti. He attended primary school in Jérémie then studied at the Centre d’Etudes Secondaire in Port au Prince. His family later moved to Boston where he completed his secondary education. Ambassador Altidor received his undergraduate degree from Boston College. He earned an MS degree from MIT in Urban Studies and Planning (2004) and also pursued graduate studies in law and economics in France.
Ambassador Altidor has an extensive private sector background. As a management consultant, he counseled firms in different countries on corporate governance and responsibility. In the aftermath of the 2010 earthquake, Ambassador Altidor led a team of professors and researchers from the Massachusetts Institute of Technology’s Community Innovators Lab down to Haiti. At the request of Haitian authorities, the team provided guidance to reconstruction officials on housing policy and financing.
Prior to the earthquake in Haiti, Ambassador Altidor worked at the International Finance Corporation (IFC) where he advised governments on infrastructure projects and public-private partnerships. He has also worked for the World Bank. Ambassador Altidor has taught at Ecole Supérieure Catholique de Droit de Jérémie (ESCDROJ), a law school in his native town of Jérémie, and he is a frequent speaker at universities in Haiti and the United States.
None altidorp@mit.edu None
Mariana Arcaya /faculty/mariana-arcaya Associate Professor of Urban Planning and Public Health Associate Department Head
Mariana Arcaya is a social epidemiologist and urban planner whose work explores dynamic relationships between geographic contexts, particularly neighborhoods, and health. Mariana conducts scholarly and policy-relevant research in two main areas: 1) bi-directional relationships between place and health, including how health considerations shape socioeconomic outcomes for individuals and communities, and, 2) applied and translational research on the social determinants of health, particularly health risk factors shaped by urban policy and planning decisions.
Prior to coming to MIT in 2015, Mariana served as a post-doctoral fellow at the Harvard Center for Population and Development Studies. She holds a Doctorate of Science from the Harvard School of Public Health, and a Master of City Planning from MIT's Department of Urban Studies & Planning. Her professional work experience includes instituting and managing a Public Health Division within Metropolitan Boston’s regional planning agency, as well as designing and overseeing the implementation of healthy urban planning strategies under a federally funded Community Transformation Grant.
9-426 marcaya@mit.edu Community Planning and Economic Development, Environmental Planning and Management, Healthy Communities and Active Living, Urban Information, Technology, and Media and AnalyticsFinlly, let’s write our scraped data to a CSV. We’ll keep it simple
and use the stock csv library—the only slight quirks here
are that we’re using the writeheader() method of the
DictWriter object to write field names. This is a standard
workflow that you’ve seen before if you’ve been following along—we open
a file, create a writer object and use it to write a row for each
iteration of some activity (here, each time a faculty member is
scraped).
import csv
output_csv = 'faculty.csv'
with open(output_csv, 'w') as f:
field_names = ['name', 'href', 'pos_1', 'pos_2', 'other_affil', 'bio', 'office', 'email', 'interests']
writer = csv.DictWriter(f, field_names)
writer.writeheader()
for person in people[0:3]:
name_href = person.find('a', class_='username')
name = name_href.get_text()
print(f'Scraping {name}...')
href = 'http://dusp.mit.edu' + name_href.get('href')
pos_1 = person.find('div', class_='views-field-field-position-and-title-1').get_text()
pos_2 = person.find('div', class_='views-field-field-position-and-title-2').get_text()
other_affil = person.find('div', class_='views-field-field-other-division').get_text()
if href:
person_soup = BeautifulSoup(requests.get(href).content, 'html.parser')
bio = person_soup.find('div', class_='pane-user-field-bio')
if bio:
bio = bio.get_text()
office = person_soup.find('div', class_='views-field views-field-field-office')
if office:
office = office.get_text()
email = person_soup.find('div', class_='views-field views-field-field-secondary-email')
if email:
email = email.get_text()
interests = person_soup.find('strong', class_='views-label views-label-field-areas-of-interest')
if interests:
interests = interests.next_sibling.next_sibling.get_text()
row = {
'name': name,
'href': href,
'pos_1': pos_1,
'pos_2': pos_2,
'other_affil': other_affil,
'bio': bio,
'office': office,
'email': email,
'interests': interests
}
writer.writerow(row)
print("Done!")Scraping Cherie Abbanat...
Done!
Scraping Paul Altidor...
Done!
Scraping Mariana Arcaya...
Done!Download Photos
As a final extension, let’s download each faculty member’s photo! We
can use the wget module to download the image, and store
the image filename in an additional field in our CSV.
# These two lines are necessary to solve a certificate verification problem.
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
if image_url:
image_url = image_url.get('src')
out_dir = os.getcwd() + '/images/'
image_file = name.replace(' ', '_').lower().replace('.', '') + '.jpg'
try:
wget.download(image_url, out_dir + image_file)
except Exception as err:
print(err, '---Could not download faculty photo.')
image_file = NoneIf you run this for all faculty photos, you’ll find that some do not allow you to download them. I’ve chatted with Duncan Kincaid about this and his diagnosis is that the DUSP webpage is powered by some fairly old infrastructure that at this point is run through with inconsistent permissions, etc. Which is good! This is exactly the kind of trouble you can get into while scraping.
import csv
import os
import wget
import time
# Same as above---these prevent certificate verification errors.
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
output_csv = 'faculty.csv'
with open(output_csv, 'w') as f:
field_names = ['name', 'href', 'pos_1', 'pos_2', 'other_affil',
'bio', 'office', 'email', 'interests', 'image_file']
writer = csv.DictWriter(f, field_names)
writer.writeheader()
for person in people[0:3]:
name_href = person.find('a', class_='username')
name = name_href.get_text()
print(f'Scraping {name}...')
href = 'http://dusp.mit.edu' + name_href.get('href')
image_url = person.find('img')
if image_url:
image_url = image_url.get('src')
out_dir = os.getcwd() + '/images/'
image_file = name.replace(' ', '_').lower().replace('.', '') + '.jpg'
try:
wget.download(image_url, out_dir + image_file)
except Exception as err:
print(err + '---Could not download faculty photo.')
image_file = None
else:
image_file = None
pos_1 = person.find('div', class_='views-field-field-position-and-title-1').get_text()
pos_2 = person.find('div', class_='views-field-field-position-and-title-2').get_text()
other_affil = person.find('div', class_='views-field-field-other-division').get_text()
if href:
person_soup = BeautifulSoup(requests.get(href).content, 'html.parser')
bio = person_soup.find('div', class_='pane-user-field-bio')
if bio:
bio = bio.get_text()
office = person_soup.find('div', class_='views-field views-field-field-office')
if office:
office = office.get_text()
email = person_soup.find('div', class_='views-field views-field-field-secondary-email')
if email:
email = email.get_text()
interests = person_soup.find('strong', class_='views-label views-label-field-areas-of-interest')
if interests:
interests = interests.next_sibling.next_sibling.get_text()
row = {
'name': name,
'href': href,
'pos_1': pos_1,
'pos_2': pos_2,
'other_affil': other_affil,
'bio': bio,
'office': office,
'email': email,
'interests': interests,
'image_file': image_file
}
writer.writerow(row)
time.sleep(1.5)Scraping Cherie Abbanat...
Scraping Paul Altidor...
Scraping Mariana Arcaya...